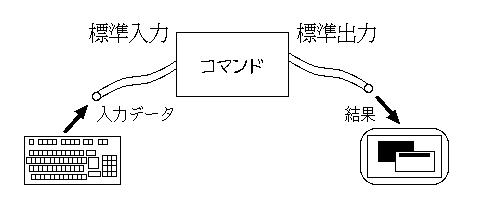
Unixでは、テキストを処理対象とするプログラムは全て標準入力から データを読み、それに処理を施した結果を標準出力に書き出すように 設計されている。
コマンドの標準入出力
コマンドをひとつだけ起動した場合、標準入力はキーボードからの入力になり、 標準出力は画面になる。しかし、Unixでは入出力の先をプログラムにしたり、 ファイルにしたりすることができる。たとえば、あるコマンドの出力を 次のコマンドの入力として与えることができる。
パイプライン
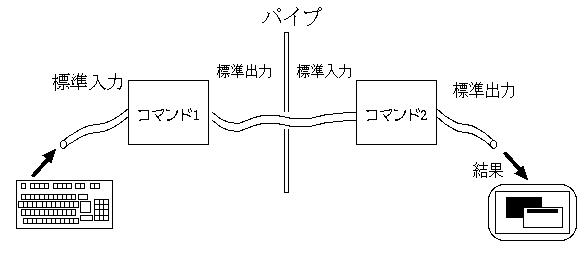
上図のように入出力をつなげるにはコマンドラインにパイプ記号
(縦棒; |)を使うだけで良い。
% コマンド1 | コマンド2
コマンド2の標準出力を、さらに別のコマンド「コマンド3」の 標準入力につなげることもでき、それは、
% コマンド1 | コマンド2 | コマンド3
と書けば良い。このように、コマンドをたくさんつなげて処理を 積み重ねて行く様子をパイプラインという。上記のコマンドラインを 実行すると「コマンド1」、「コマンド2」、「コマンド3」が同時に起動され 「コマンド1」から出力が発生すると同時に「コマンド2」にデータが渡される。 同様に、コマンド2からの出力が発生すると即座にコマンド3にデータが渡される。
Unixには「並べ換え」、「文字の置き換え」、「項目の切り出し」 などの一つの処理に特化したコマンドがいくつも用意されていて、それらを パイプラインによって組み合わせることで、複雑な処理を行なえるように なっている。
まずは、日本全国の郵便番号を全て記録したファイル zip_jp.txt
をコピーしよう。このファイルはサーバマシン上の
~yuuji/zip_jp.txt にあるので以下のようにコピーする。
% cp ~yuuji/zip_jp.txt .
cpコマンドがエラーを出さなかったら、ls
コマンドでコピーできているか確認する。
% ls
zip_jp.txt というファイル名が見えれば成功している。
このファイルの中味を見てみよう。
% less zip_jp.txt
このファイルは、全国全ての郵便番号が1行に1つずつ記録されている。 全ての行は空白で項目が区切られていて、なおかつどの行も全く同じ項目並びで 構成されている。このファイルはTAB区切りと呼ばれる書式で、 データベースの保存形式として利用されることがあるものである。Exelなどの 表計算ソフトでも読み込むことができる。
lessを終了するにはアルファベットの q をタイプする。
全日本郵便番号ファイルに含まれる件数はwcコマンドで
調べることができる。
% wc zip_jp.txt
121647 1824705 12319648 zip_jp.txt
一番左の121647が総件数で、約12万件のデータが含まれていることになる。 このなかから「左沢」を含むデータ(正確にはレコードという)を 探してみよう。egrepコマンドのパターンとして 左沢 を指定するだけで良い。 パターンはクォーテーションマーク ' でくくることに注意。
% egrep '左沢' zip_jp.txt
探し出せただろうか。
ちなみに、上記の検索にかかる時間を計るにはコマンド実行の前に
time という単語をつければ良い。
% time egrep '左沢' zip_jp.txt
(検索結果)
egrep '左沢' zip_jp.txt 0.22s user 0.14s system 95% cpu 0.375 total
この例では0.375秒かかった。
12万件からの検索が0.4秒なのは速度的にはさほど速くない。 それよりもむしろファイルを開いて検索して結果を得るまでのトータルの時間が 短いこと、結果を別のコマンドに渡せることに優位性がある。
1行全てを表示するのではなく、7桁郵便番号と市区名と 町名だけを切り出してみよう。
awkコマンドを使うと、空白で項目が区切られた入力レコードから
指定した項目だけを切り取って出力することができる。以下のコマンドを
実行してみよう。結果が大量なので、lessコマンドで1ページずつ表示を
止めて確認しよう。
% awk '{print $3,$8,$9}' zip_jp.txt | less
これは、「zip_jp.txt ファイルから、第3項目、第8項目、
第9項目のみを出力(print)せよ」ということを意味している。
続いて郵便番号を基準として並べ換えてみよう。
gsortコマンドは標準入力を読み込み、それらの行を指定した
項目番号で並べ換える。項目番号はとくに指定しなければ先頭(第1項目)と
見なされる。
先ほどのコマンドライン
% awk '{print $3,$8,$9}' zip_jp.txt | less
は以下のようになる。
0640941 札幌市中央区 旭ケ丘 0600041 札幌市中央区 大通東 0600042 札幌市中央区 大通西(1〜19丁目) 0640820 札幌市中央区 大通西(20〜28丁目) 0600031 札幌市中央区 北一条東 0600001 札幌市中央区 北一条西(1〜19丁目) 0640821 札幌市中央区 北一条西(20〜28丁目) 0600032 札幌市中央区 北二条東 0600002 札幌市中央区 北二条西(1〜19丁目) 0640822 札幌市中央区 北二条西(20〜28丁目) : :
これは
となっている。これを第1項目の郵便番号で並べ換えるには 以下のように実行する。
% awk '{print $3,$8,$9}' zip_jp.txt | gsort -n | less
逆順に並べ換えたいときは gsort コマンドに逆順を
司令する -r オプションを追加する。
% awk '{print $3,$8,$9}' zip_jp.txt | gsort -nr | less
awk, gsort コマンド、いずれもコンピュータのメモリの許す
限り何件でもデータを処理することができる。
→ 目次